
The educational technology collective is a group of students, staff, and faculty who explore the intersections of technology with teaching, learning, and education, with a particular focus on learning analytics, educational data mining, and collaborative engagement. We’re interdisciplinary, and include researchers with backgrounds in computer science, information, psychology, statistics, and more.
Interested in hearing more about what we do? Check out the projects listed below to see where you might fit, and contact the lead researcher to see what opportunities might exist for volunteering, part time work, or independent study. Or browse our github for current public codebases, or scholarly publications below, to get a sense of how we’re trying to build better education.
















Understanding the nuances of a student’s education requires looking beyond single metrics and datasets. Despite being driven by a common goal of using data-driven inquiry to positively affect teaching and learning in higher education, our methods, tools, and data are different. As a result, we aim to tackle these issues by connecting various forms of knowledge representations from a variety of disciplinary methodologies to construct a holistic model of education.
Some examples of projects we’re working on include: building explanatory models to identify underlying causes of success for next-generation intervention systems and creating infrastructure for querying indicators of student achievement across disparate datasets in order to facilitate research.
Project leads: Christopher Brooks, with SI faculty Stephanie Tealsey and Kevyn Collins-Thompson, LSA faculty Tim McKay and Gus Evrard, and AOS faculty Perry Samson

The Mentor Academy is a data-science learning community of practice where students volunteer their knowledge, skills, and time to give back to new students. Built around the content of the Applied Data Science with Python online course on Coursera, students are able to give back by creating new culturally relevant problem sets for online learners or engaging in mentorship in discussion forums.
The first cohort of mentors for the Mentor Academy were recruited in October 2017. The next iteration of the academy is in planning.
Project leads: Anant Mittal and Christopher Brooks
The growing popularity of Data Science courses demands more research on their pedagogy and assessment practices. Based on insights gained from the analysis of students’ programming assignment submissions in a Data Manipulation course (offered in an online Master of Applied Data Science program), this project explores the common errors and misconceptions that learners encounter while engaging in notebook-based introductory data science programming exercises.
We are now collaborating with Microsoft to build a human-AI collaborative tool that generates feedback on students’ data science programming mistakes. A pilot of this tool was deployed in the Fall’22 and Winter’23 offerings of the Data Manipulation course.
Project Leads: Anjali Singh and Christopher Brooks
Collaborators: PROSE team at Microsoft
Learnersourcing, a form of crowdsourcing where learners engage in learning activities while contributing useful inputs for other learners, is emerging as an effective technique for the generation of teaching and learning resources at scale. In this project, we take a student-centric approach to understand how we can design learnersourcing systems where students value the learnersourcing task, learn deeply, and generate high-quality output.
In Fall’20, we conducted a large-scale field experiment in the MOOC Introduction to Data Science in Python to study the effects of learnersourcing on students who create Multiple Choice Questions (MCQs) and their motivations for engaging in question generation.
We are now exploring the use of learnersourcing for generating feedback messages by prompting students to reflect on their mistakes in data science programming assignments.
Project Leads: Anjali Singh and Christopher Brooks
Smart home technologies are transforming childhood profoundly by shifting children’s play, learning, and social interaction to the digital realm. This development introduces privacy and safety risks for children. Smart speakers, wearables, even smart vacuums, capture data about children and their families for powering services and experiences, profiling, analytics, and commercial purposes – often without transparent communication of data practices. Children’s healthy development and self-identity rely on a safe and privacy-friendly (smart) home environment.
This line of research aims to understand children’s understanding of smart home related privacy and safety risks and explore age-appropriate ways to SUPPORT children and parents’ understanding and management of such digital privacy and safety risks.
Project leads: Kaiwen Sun, Chris Brooks, Florian Schaub
Computational notebooks enable data scientists to document their exploration process through a combination of code, narrative text, visualizations, and other rich media. The rise of big data has increased the demand for data scientists degree programs in colleges, as well as data science MOOCs. In data science classrooms, instructors use computational notebooks to demonstrate code and its output. While learners navigate example notebooks to enhance their perceived knowledge from watching video lectures, or create their own notebooks for assignments or capstone projects. In the Educational Technology Collective, we reflect on the current practice of computational notebooks in data science courses and explore the opportunities and challenges of better adapting computational notebooks for data science education. In particular, we have several projects on redesigning computational notebooks for supporting real-time group collaboration, facilitating joint discourse over shared context, and encouraging active learning.
Project leads: April Wang, Christopher Brooks, and Steve Oney
Collaborators: Anant Mittal and Zihan Wu
Self-regulated learning (SRL) is the process where a learner monitors and controls metacognition, cognition, motivation, affect, and contextual factors to achieve goals (Boekaerts & Niemivirta, 2000; Greene & Schunk, 2017; Pintrich, 2000; Winne, 2001; Zimmerman, 2000). SRL process includes numerous goal-oriented actions from building strategies to tackle a given task to evaluate learners’ performance. Researchers who study SRL should carefully align their study design with these common features, regardless of which models they use as a fundamental theoretical base for the study. In particular, alignment between measures and theory is important, because SRL measures indicate how researchers understand and model SRL processes (Greene & Azevedo, 2010). Because of the importance of alignment between measurements and SRL models, there have been discussions on how to verify and improve the validity of measurements detecting SRL components. Through the study, I will investigate the validity issues of SRL measures used in previous studies and discuss the current approaches to resolving the issues. Furthermore, I will focus on systems for investigating the validity of trace data and self-report data on learners’ help-seeking strategy usages.
Project Leads: Heeryung Choi and Christopher Brooks
Advances in artificial intelligence, coupled with extensive data collection provide unparalleled insights into determinants of every-day activities. In education this has spawned research on predictive modeling of learning success, which are used to power early warning systems. They can be used to identify students who are at-risk of failing or dropping out of a course, and to intervene if necessary. However, because the effectiveness of these systems rests upon the collection of student data, including sensitive information and confidential records, this creates a tension between developing effective predictive models while supporting learners’ agency and privacy.
In our research, we are interested in finding out students’ views on the collection and use of their educational records, as well as their overall privacy perceptions and how this, combined with personal background and academic information, may be tied to one’s propensity to opt-in or opt-out of having their data collected for the purposes of predictive modeling. These findings may impact institutions’ abilities to help identify “at-risk” students, suggest possible intervention strategies, and to contextualize opt-in or opt-out, thereby impacting how they choose to interact with students. We also gain a better understanding of whether students are aware about how their personal data is used, how the use of this data should be managed, and how these decisions impact predictive models’ performance.
Project Leads: Warren Li, Kaiwen Sun, Florian Schaub, and Christopher Brooks
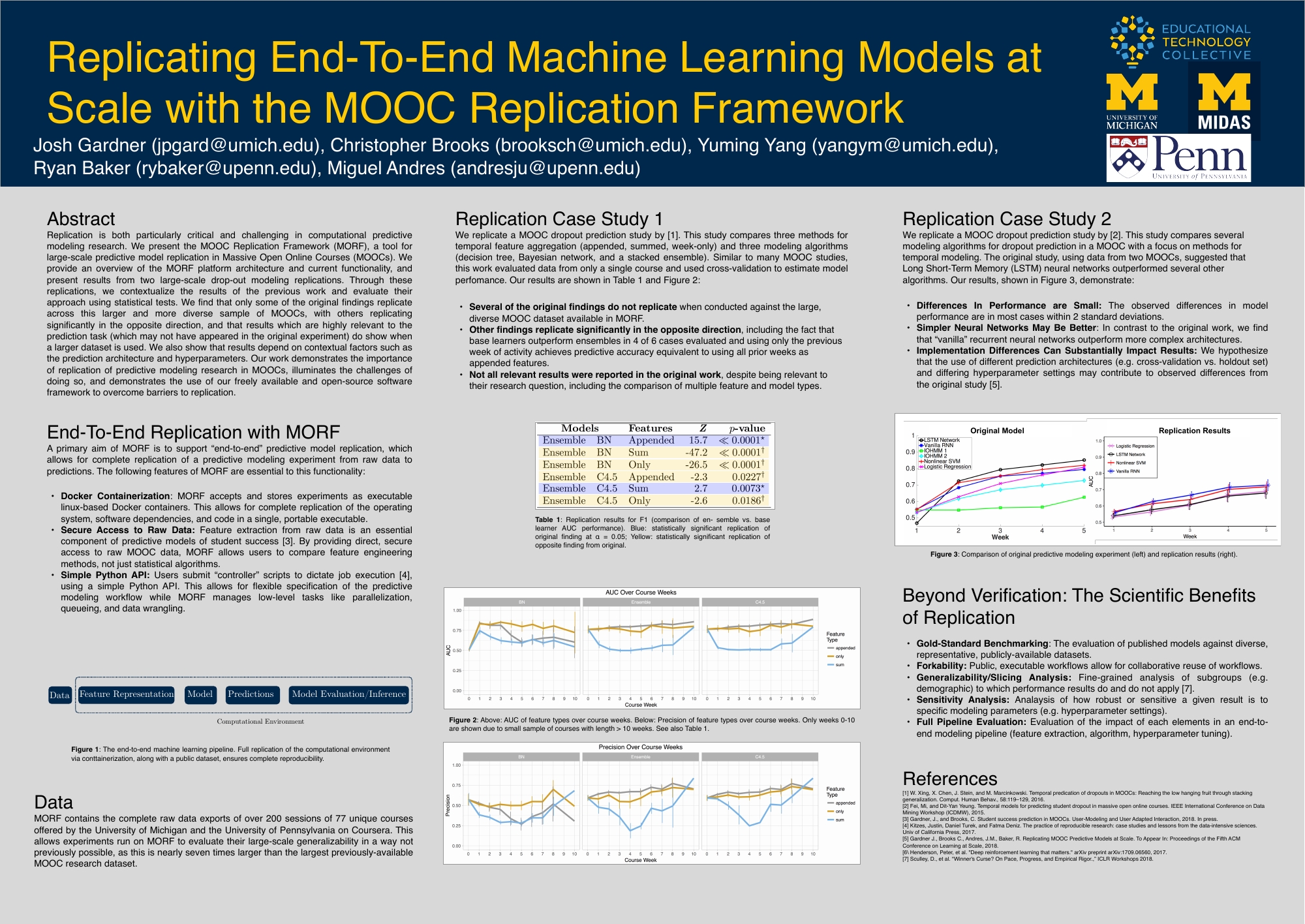
Whether machine-learned, human generated, or a hybrid, models of student success in education need to be replicated in new contexts and datasets in order to ensure generalizability . We’re building the software to do this, and hooking it up to large datasets of hundreds of classes with millions of learners through collaboration between the University of Michigan and the University of Pennsylvania.
Links for more information
Project leads: Josh Gardner and Christopher Brooks
Can't see the publication list? Check out our google doc
Gardner, J., Yu, R., Nguyen, Q., Brooks, C., and Kizilcec, R. (2023). Cross-Institutional Transfer Learning for Educational Models: Implications for Model Performance, Fairness, and Equity. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT '23). Association for Computing Machinery, New York, NY, USA, 1664–1684. https://doi.org/10.1145/3593013.3594107
Singh, A., Fariha, A., Brooks, C., Soares, G., Henley, A., Tiwari, A., Mahadevaswamy, C., Choi, H., and Gulwani, S. (2024). Investigating Student Mistakes in Introductory Data Science Programming. To Appear In Proceedings of SIGCSE’24.
Wang, A., Head, A., Zhang, A., Oney, S., Brooks, C. (2023). Colaroid: A Literate Programming Approach for Authoring Explorable Multi-Stage Tutorials. Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI 2023). DOI:https://doi.org/10.1145/3576050.3576052
Choi, H., Jovanovic. J, Poquet. O, Brooks, C., Joksimovic. S, Williams. J (2023). The Benefit of Reflection Prompts for Encouraging Learning with Hints in an Online Programming Course. Internet and Higher Education. DOI: https://doi.org/10.1016/j.iheduc.2023.100903
Choi, H., Winne. P, Brooks, C., Li, W., Shedden. K (2023). Logs or Self-Reports? Misalignment Between Behavioral Trace Data and Surveys When Modeling Learner Achievement Goal Orientation. Proceedings of the 13th International Conference on Learning Analytics and Knowledge (LAK23) 11-21. DOI: https://doi.org/10.1145/3576050.3576052
Sun, K., Zou, Y., Radesky, J., Brooks, C., Schaub, F. (2021). Children Safety in the Smart Home: Parents’ Perceptions, Needs, and Mitigation Strategies. Proceedings of the ACM: Human-Computer Interaction, Computer-Supported Cooperative Work and Social Computing (CSCW). DOI: https://doi.org/10.1145/3479858 Presented at PrivacyCon 2022
Hutt, S., Baker, R. S., Ashenafi, M. M., Andres-Bray, J. M. & Brooks, C. (2022). Controlled outputs, full data: A privacy-protecting infrastructure for MOOC data. British Journal of Educational Technology, 53, 756– 775. https://doi.org/10.1111/bjet.13231
Sun, K., Zou, Y., Li, J., Brooks, C., Schaub, F. (2022). The Portrayal of Children in Smart Home Marketing. Workshop on Kids' Online Privacy and Safety (KOPS 2022) at Symposium on Usable Privacy and Security (SOUPS). August, 2022. Boston, MA, USA.
Brooks, C., Thompson, C. (2022). Predictive Modelling in Teaching and Learning. In C. Lang, G. Siemens, A. F. Wise, D. Gasevic, & A. Merceron (Eds.), The Handbook of Learning Analytics (2nd Edition, 29–37). Available at https://www.solaresearch.org/publications/hla-22/hla22-chapter3/
Singh, A., Brooks, C., Doroudi, S. (2022) Learnersourcing in Theory and Practice: Synthesizing the Literature and Charting the Future. Proceedings of the Ninth ACM Conference on Learning@ Scale. 2022. https://dl.acm.org/doi/abs/10.1145/3491140.3528277
Wang, A., Epperson, W., DeLine, R., Drucker, S. (2022). Diff in the Loop: Supporting Data Comparison in Exploratory Data Analysis. Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI 2022).
Wang, A., Wang, D., Drozdal, J., Muller, M., Park, S., Weisz, J., Liu, X., Wu, L., Dugan, C. (2022). Documentation Matters: Human-Centered AI System to Assist Data Science Code Documentation in Computational Notebooks. ACM Trans. Comput.-Hum. Interact. 29, 2, Article 17 (April 2022), 33 pages. DOI: https://doi.org/10.1145/3489465 (TOCHI).
Choi, H., Mills, C., Brooks, C., Doherty, S., Singh, A. (2021). Design recommendations for using textual aids in data-science programming courses. In Proceedings of the 53rd ACM Technical Symposium on Computer Science Education (SIGCSE). DOI: https://doi.org/10.1145/3478431.3499290
Li, W., Sun, K., Schaub, F., Brooks, C. (2021). Disparities in Students’ Propensity to Consent to Learning Analytics. International Journal of Artificial Intelligence in Education (IJAIED). https://link.springer.com/article/10.1007/s40593-021-00254-2
Wang, A., Chen, Y., Chung, J., Brooks, C., Oney, S. (2021). PuzzleMe: Leveraging Peer Assessment for In-Class Programming Exercises. Proceedings of the ACM: Human-Computer Interaction, Computer-Supported Cooperative Work and Social Computing (CSCW). https://dl.acm.org/doi/pdf/10.1145/3479559
Sun, K., Zou, Y., Radesky, J., Brooks, C., Schaub, F. (2021). Children Safety in the Smart Home: Parents’ Perceptions, Needs, and Mitigation Strategies. Proceedings of the ACM: Human-Computer Interaction, Computer-Supported Cooperative Work and Social Computing (CSCW). DOI: https://doi.org/10.1145/3479858
Singh, A., Brooks, C., Lin, Y., Li, W. (2021). What's In It for the Learners? Evidence from a Randomized Field Experiment on Learnersourcing Questions in a MOOC. Proceedings of the Eighth (2021) ACM Conference on Learning@ Scale. 2021. [Best Paper Award] https://dl.acm.org/doi/10.1145/3430895.3460142
Nguyen, Q., Brooks, C., Poquet, Q. (2021). Identifying friendship layers in peer interactions on campus from spatial co-occurrences. Paper presented at AERA 21, Division D - Measurement and Research Methodology/Division D - Section 2: Quantitative Methods and Statistical Theory.
Singh, A. (2020). Investigating the Benefits of Student Question Generation in Data Science MOOC Assessments. In Proceedings of the 2020 International Computing Education Research Conference (ICER ’20), Virtual Event, New Zealand, August 10–12, 2020. https://dl.acm.org/doi/pdf/10.1145/3372782.3407115
Nguyen, Q., Poquet, O., Brooks, C., Li, W. (2020). Exploring homophily in demographics and academic performance using spatial-temporal student networks. Paper presented at the Educational Data Mining (EDM 2020).
Singh, A., Aggarwal, A., Ericson, B., Brooks, C. (2020). Understanding Students’ Behavioral Patterns on Interactive E-books using Doc2vec Embeddings. Poster presented at the AERA Satellite Conference on Educational Data Science, Stanford University, September 18, 2020
Nguyen, Q., Li, W., Brooks, C. (2020). Modelling students’ social network structure from spatial-temporal network data. Poster presented at AERA Satellite Conference on Educational Data Science, Stanford University, April 22-23, 2020.
Wang, A., Wu, Z., Brooks, C., Oney, S. (2020). Callisto: Capturing the Why by Connecting Conversations with Computational Narratives. Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI 2020). April 25-30, Honolulu, HI. [Honourable Mention Award]
Nguyen, Q. (2020). Rethinking time-on-task estimation with outlier detection accounting for individual, time, and task differences. Proceedings of the 10th International Conference on Learning Analytics and Knowledge (LAK20) to be held in Frankfurt am Main, Germany, March 23-27, 2020.
Nguyen, Q., Rienties, B., Richardson, J.T.E. (2019). Learning analytics to uncover inequality in behavioural engagement and academic attainment in a distance learning setting. Assessment & Evaluation in Higher Education, 1-13.
Wang, A., Mittal, A., Brooks, C., Oney, S. (2019). How Data Scientists Use Computational Notebooks for Real-Time Collaboration. Proceedings of the ACM: Human-Computer Interaction, Computer-Supported Cooperative Work and Social Computing (CSCW). November 9-13, Austin, TX. [Best Paper Award]
Quintana, R.M., Brooks, C., Smothers, C., Tan, Y. (2019). Engaging MOOC Learners in the Creation of Data Science Problems. Presented in the “Innovating MOOC Pedagogies” structured poster session at the Annual Meeting of the American Educational Research Association (AERA). April 5-8. Toronto, Ontario.
Dowell, N., Lin, Y., Godfrey, A., Brooks, C. (2019). Promoting Inclusivity through Time-Dynamic Discourse Analysis in Digitally-Mediated Collaborative Learning. 20th International Conference on Artificial Intelligence in Education (AIED 2019). June 25-29, Chicago, IL.
Wang, A., Oney, S., Brooks, C. (2019). Redesigning Notebooks for Data Science Education. Workshop on Human-Centered Study of Data Science Work Practices at ACM Conference on Human Factors in Computing Systems (CHI19). May, 2019. Glasgow, UK. Workshop Paper
Mittal, A., Brooks, C. (2019). Augmenting Authentic Data Science Environments for Learning Analytics. 9th International Conference on Learning Analytics and Knowledge 2019 (LAK19). March, 2019. Tempe, AZ, USA. Poster.
Sun, K., Mhaidli, A.H., Watel, S., Brooks, C., Schaub, F. (2019). It’s My Data! Tensions Among Stakeholders of a Learning Analytics Dashboard. ACM Conference on Human Factors in Computing Systems (CHI19). May, 2019. Glasgow, UK. DOI: https://dl.acm.org/doi/abs/10.1145/3290605.3300824
Lin, Y., Dowell, N., Godfrey, A., Choi, H., Brooks, C. (2019). Modeling gender dynamics in intra and interpersonal interactions during online collaborative learning. 9th International Conference on Learning Analytics and Knowledge 2019 (LAK19). March, 2019. Tempe, AZ, USA.
Yan, W., Dowell, N., Holman, C., Welsh, S., Choi, H., Brooks, C. (2019). Exploring Learner Engagement Patterns in Teach-Outs: Using Topic, Sentiment and On-topicness to Reflect on Pedagogy. 9th International Conference on Learning Analytics and Knowledge 2019 (LAK19). March, 2019. Tempe, AZ, USA.
NeCamp, T., Gardner, J., Brooks, C. (2019). Beyond A/B Testing: Sequential Randomization for Developing Interventions in Scaled Digital Learning Environments. 9th International Conference on Learning Analytics and Knowledge 2019 (LAK19). March, 2019. Tempe, AZ.
Li, W., Brooks, C., Schaub, F. (2019). The Impact of Student Opt-Out on Educational Predictive Models. 9th International Conference on Learning Analytics and Knowledge (LAK19). March, 2019. Tempe, AZ.
Gardner, J., Brooks, C., Baker, R. (2019). Evaluating the Fairness of Predictive Student Models Through Slicing Analysis. 9th International Conference on Learning Analytics and Knowledge (LAK19). March, 2019. Tempe, AZ. [Best Full Paper Award]
Choi, H., Dowell, N., Brooks, C., Teasley, S. (2019). Social Comparison in MOOCs: Perceived SES, Opinion, and Message Formality. 9th International Conference on Learning Analytics and Knowledge 2019 (LAK19). March, 2019. Tempe, AZ.
NeCamp, T., Gardner, J., Brooks, C. (2018). Sequential Randomization to Develop Personalized and Optimized Interventions in Massively Open Online Courses: A Case Study. Conference on Digital Experimentation (CODE). October, 2018. Boston, MA.
Sun, K., Mhaidli, A., Watel, S., Brooks, C., Schaub, F. (2018). Taking Student Data for Granted? A Multi-Stakeholder Analysis of a Learning Analytics System. The 11th International Conference on Educational Data Mining. July, 2018. Buffalo, NY, USA. Workshop Paper. Full Paper.
Sun, K., Mhaidli, A., Watel, S., Brooks, C., Schaub, F. (2018). Taking Student Data for Granted? A Multistakeholder Privacy Analysis of a Learning Analytics System. Symposium on Usable Privacy and Security (SOUPS). August, 2018. Baltimore, MD, USA. Poster.
Gardner, J., Yang, Y., Baker, R.S., Brooks, C. (2018). Enabling End-To-End Machine Learning Replicability: A Case Study in Educational Data Mining. Workshop on Enabling Reproducibility in Machine Learning at the Thirty-fifth International Conference on Machine Learning. arXiv. Github.
Gardner, J., Brooks, C. (2018). Evaluating Predictive Models of Student Success: Closing the Methodological Gap. Journal of Learning Analytics 5(2), special issue on methodological issues in learning analytics. arXiv preprint arXiv:1801.08494.
Gardner, J., Brooks, C. (2018). Student success prediction in MOOCs. User Modeling and User Adapted Interaction (UMUAI) 28.2: 127-203. Full Paper.
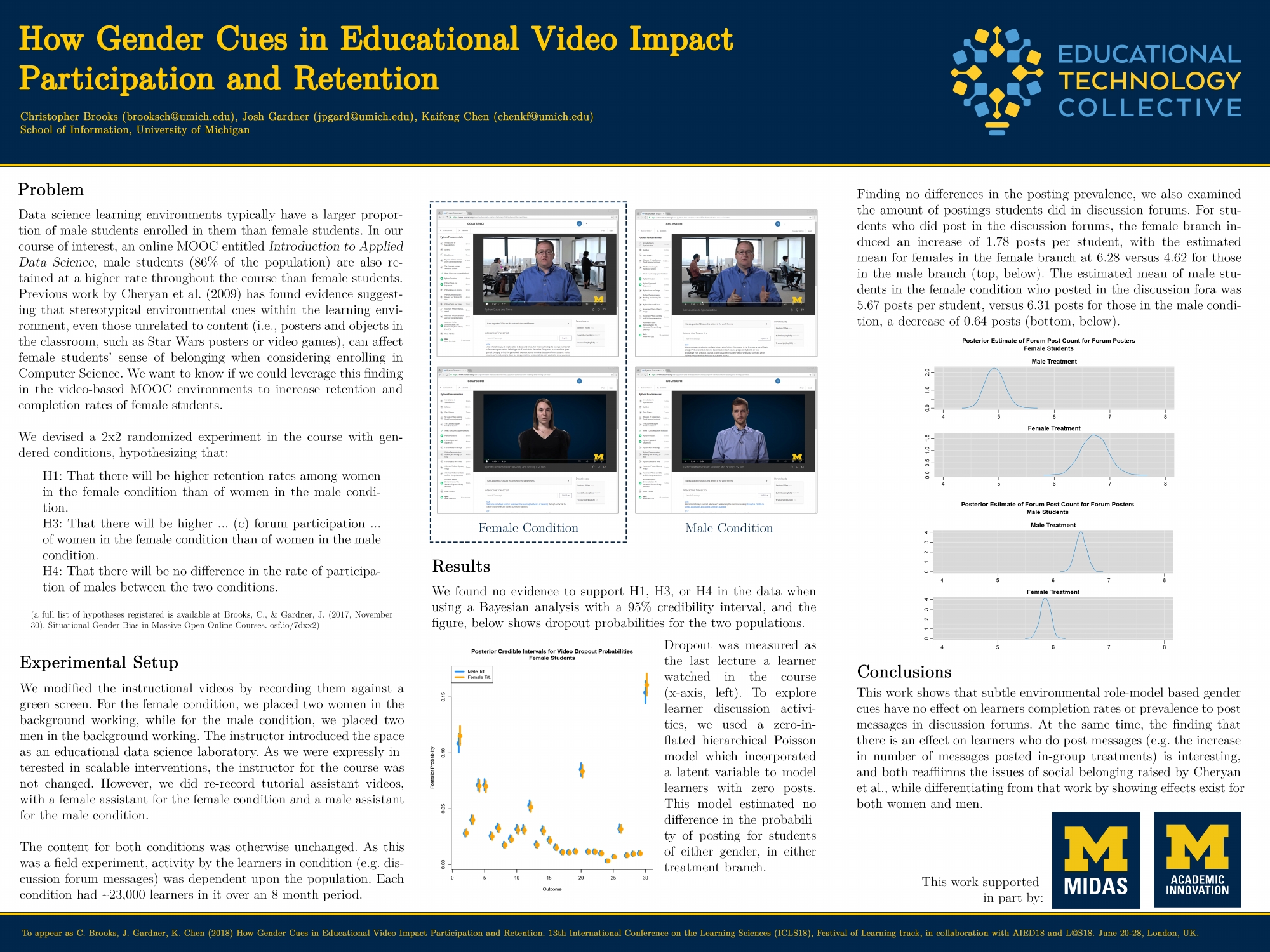
Brooks, C., Gardner, J., Chen, K. (2018). How Gender Cues in Educational Video Impact Participation and Retention. Festival of Learning, June, 2018. London UK. Full Crossover Paper.
Dowell, N. M., Nixon, T., & Graesser, A. C. (2018). Group communication analysis: A computational linguistics approach for detecting socio cognitive roles in multi-party interactions. To appear in: Behavior Research Methods. doi:10.3758/s13428-018-1102-z. Preprint
Dowell, N. M., Brooks, C., Poquet, O. (2018). Digital Traces Of Identity in Online Discourse: Detecting Socio-Cognitive Roles with Group Communication Analysis. 48th annual meeting of the Society for Computers in Psychology, New Orleans, LA.
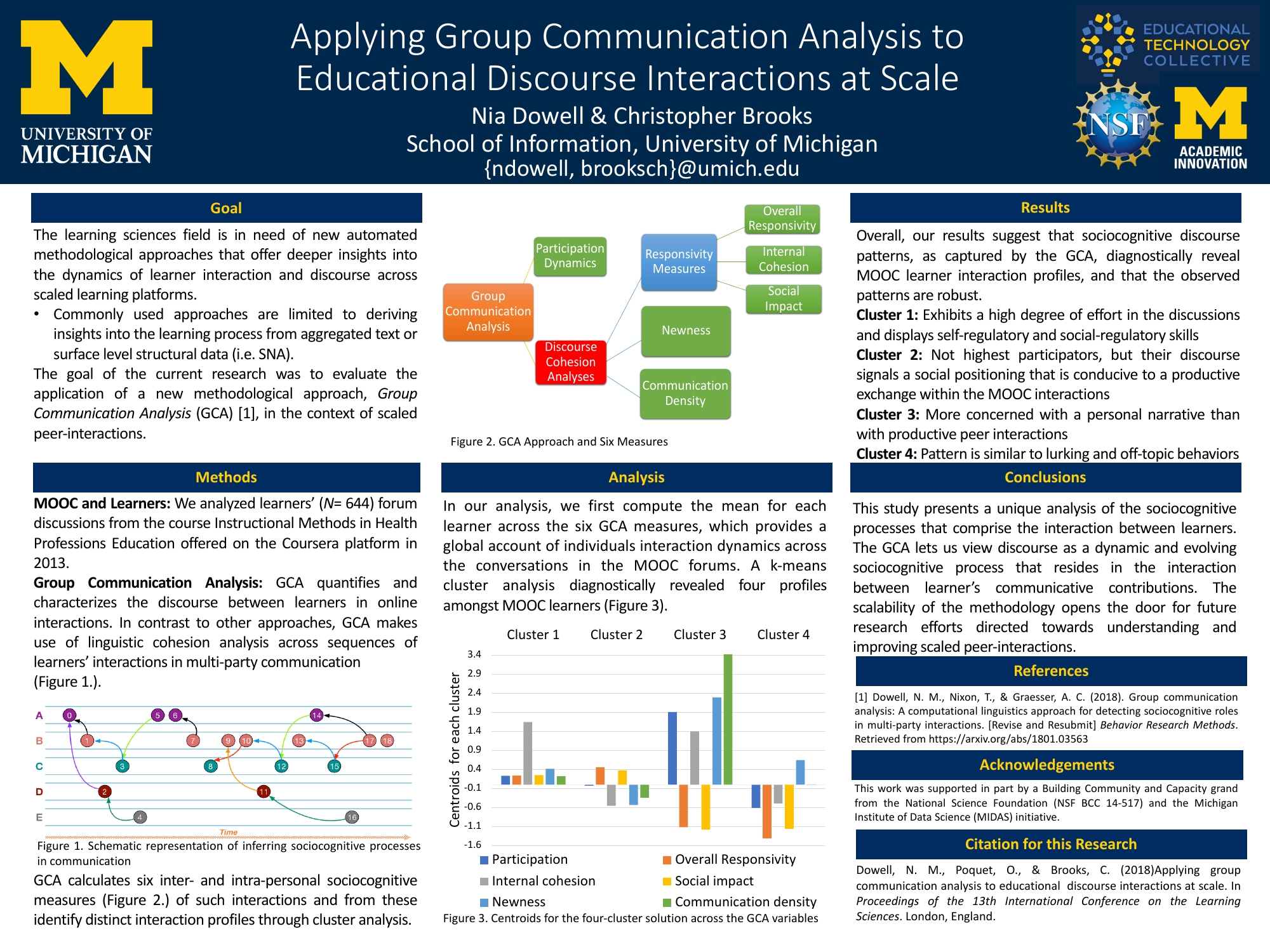
Dowell, N. M., Poquet, O., Brooks, C. (2018). Applying group communication analysis to educational discourse interactions at scale. 13th International Conference of Learning Science 2018 (ICLS18). June, 2018. London, UK. Full Crossover Paper.
Gardner, J., Brooks, C., Andres, J.M.L., Baker, R. Replicating MOOC Predictive Models at Scale. Fifth Annual Meeting of the ACM Conference on Learning@Scale; June 2018; London, UK. Full Paper.
Hu, J., Dowell, N., Brooks, C. (2018). Temporal Changes in Affiliation and Emotion in MOOC Discussion Forum Discourse. 19th International Conference on Artificial Intelligence in Education (AIED18). June, 2018. London, UK. Poster.
Choi, H., Dowell, N., Brooks, C. (2018). Social Comparison Theory as Applied to MOOC Student Writing: Constructs for Opinion and Ability. 13th International Conference of Learning Science 2018 (ICLS18). June, 2018. London, UK. Poster.
Hui, L., Siek, B., Brooks, C. (2018). Scaling MOOC Discourse Analysis with In Situ Coding. 8th International Conference on Learning Analytics and Knowledge 2018 (LAK18). March, 2018. Sydney, Australia. Demo.
Poquet, O., Dowell, N., Brooks, C., Dawson, S. (2018) Are MOOC forums changing? 8th International Conference on Learning Analytics and Knowledge 2018 (LAK18). March, 2018. Sydney, Australia. Full Paper.
Gardner, J., Brooks, C. (2018) Coenrollment Networks and their Relationship to Grades in Undergraduate Education. 8th International Conference on Learning Analytics and Knowledge 2018 (LAK18). March, 2018. Sydney, Australia. Full Paper.
Gardner, J., Brooks, C. (2018) MOOC Dropout Model Evaluation. Eighth Symposium on Educational Advances in Artificial Intelligence 2018 (EAAI-18). February 3-4, 2018; New Orleans, LA. Full Paper.
Joksimovic, S., Poquet, S., Kovanovic, V., Dowell, N., Mills, C., Gasevic, D., Dawson, S., Graesser, A.C., Brooks, C. (2017) How Do We Model Learning at Scale? A Systematic Review of Research on MOOCs. Review of Educational Research. Vol 88, Issue 1, pp. 43-86 doi: 10.3102/0034654317740335. Full Paper.
Gardner, J., Brooks, C. A Statistical Framework for Predictive Model Evaluation in MOOCs. Proceedings of the Fourth (2017) ACM Conference on Learning@ Scale. ACM, 2017. Work-In-Progress Paper.
Gardner, J., Brooks, C. Toward Replicable Predictive Model Evaluation in MOOCs. Proceedings of the 10th International Conference on Educational Data Mining. 2017. Poster Paper.
Gardner, J., Brooks, C. Statistical approaches to the model comparison task in learning analytics. Proceedings of the First Workshop on Methodology in Learning Analytics (MLA). 2017. Workshop Paper.
Choi, H., Brooks, C., Collins-Thompson, K. What does student writing tell us about their thinking on social justice? Proceedings of the Seventh International Learning Analytics & Knowledge Conference. ACM, 2017. Poster Paper.
Gardner, J., Onuoha, O., Brooks, C. Integrating syllabus data into student success models. Proceedings of the Seventh International Learning Analytics & Knowledge Conference. ACM, 2017. Poster Paper.
Brooks, C., Quintana, R., Hui, L. Engaging MOOC Learners as Lifelong Collaborators. Workshop on Integrated Learning Analytics of MOOC Post-Course Development. Workshop at the 7th International Learning Analytics and Knowledge Conference. Simon Fraser University, Vancouver, Canada, 13-17 March 2017, p. 125-129.
Choi, H., Wang, Z., Brooks, C., Collins-Thompson, K., Reed, B.G., Fitch, D. (2018). Social work in the classroom? A tool to evaluate topical relevance in student writing. 10th International Conference on Educational Data Mining; June 2017; Wuhan, CN. Poster Paper.
Gardner, J., Brooks, C. Predictive Models with the Coenrollment Graph: Network-Based Grade Prediction in Undergraduate Courses. The Third International Workshop on Graph-Based Educational Data Mining at 10th International Conference on Educational Data Mining; June 2017; Wuhan, CN. Workshop Paper.
Dowell, N. M., Brooks, C., Kovanovic, V., Joksimovic, S., Gasevic. D. The changing patterns of MOOC discourse. Proceedings of the Fourth (2017) ACM Conference on Learning@ Scale. ACM, 2017. Work-In-Progress Paper.






